
Unlocking the Power of Large Language Models Locally with Ollama
- Dwain Barnes
- Nov 17, 2024
- 4 min read
Updated: Nov 21, 2024

Introduction
Imagine having your own personal ChatGPT like LLM models right at your fingertips running locally and private not in a distant cloud and no expensive API costs but running directly on your own computer. That’s exactly what Ollama offers. For someone like me, who’s spent countless hours wrestling with cloud-based APIs and configurations, discovering Ollama felt like stumbling onto a treasure trove of simplicity and efficiency.
Let’s take a journey together to explore how Ollama works, why it’s a game-changer, and how you can start using it today.
Why Large Language Models Matter
If you’ve ever used ChatGPT you have probably know how useful it can be, it can draft an email, write a piece of code, or brainstorm creative ideas. However services like ChatGPT can be expensive and require an internet connection, There is also the issue of how sensitive information is handled, it’s not private and it’s not something not everyone has easy access to.
I remember the first time I tried setting up an LLM for local use around 2 years ago. It felt like was quite complex for some one without prior coding knowledge, dependencies mismatches, configurations failures, and I couldn’t shake the feeling that there must be an easier way. Then I discovered Ollama.
What Is Ollama?
Ollama is an open-source tool designed to make setting up and running large language models on local machines straightforward. It removes the complexity of traditional setups, allowing developers to use powerful LLMs without relying on external servers or elaborate configurations.
Key Features That Stand Out
Access to Pre-Built Models
Ollama provides pre-built models like Llama 3.2, Gemma, and Mistral, ready to use. You can also bring your own models and customise this feature will be shown later. You now also have access thousands of GGUF models on Hugging Face Hub.
For example suppose you’re a content creator. You can use Llama 3 to generate draft ideas, while Mistral might help you fine-tune technical explanations for your audience.
Customizable Setup
Ollama’s Modelfile allows you to tweak settings like model parameters and behavior.
Privacy and Performance
Running models locally means your data never leaves your device. Plus, if you’ve got a GPU, Ollama takes full advantage of it for faster processing.
Relatable Scenario
Let’s say you’re a small business owner brainstorming taglines. With Ollama, you can work with sensitive customer data without worrying about leaks or breaches.
No Interent Required
Once the model has been download you can run it locally with out any internet connection.
Cost Savings
Say goodbye to monthly subscriptions. Once you set up Ollama, you can use it as much as you want without worrying about additional fees.
OpenAI compatable API
If you are a programmer, you can get programmatic access to your models.
Getting Started: A Step-by-Step Guide for Windows
For Windows Users
Download the Installer

Head to the official website https://ollama.com/download/windows and grab the setup file.
Install with Ease

Run the downloaded .exe file and follow the instructions. Once installed, Ollama operates in the background, ready whenever you need it.

Run Your First Model
Open the command prompt and type:
ollama run llama3.2it will download the model and Voilà! Your first model is up and running.
Ollama Library
Ollama's Model Library offers a diverse range of LLM models, You can browse the library or use the search function. I will use Gemma 2. as an example
1. Accessing the Model Library
Visit the Library:

Navigate to the Ollama Model Library to explore available models.
Search for Gemma 2
Use the search bar or browse the listings to find Gemma 2.
2. Selecting the Gemma 2 Model
Open the Model Page

Click on Gemma 2 to view detailed information, including parameter sizes and intended usage.
Review Model Details:
Gemma 2 is available in three sizes. This is selectable by using the drop down menu.
2B Parameters: Suitable for lightweight applications.
9B Parameters: Balances performance and resource requirements.
27B Parameters: Offers superior performance, surpassing models more than twice its size in benchmarks.
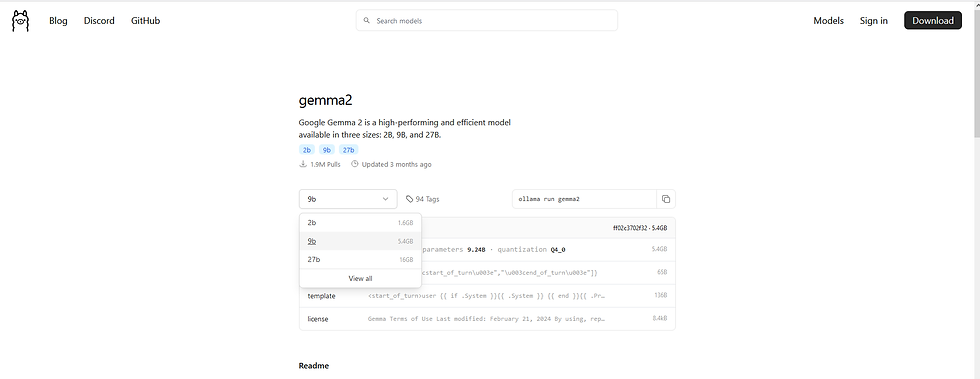
Lets select 2b as that can run on low end hardware.
Downloading the selected model

Once we have selected 2b, copy the run command by clicking the highlighted icon. Open up command prompt and paste and run the command.

To list the models you have successfully downloaded, use the command.
ollama list
Hugging Face Models with Ollama
There are 45,000 public GGUF checkpoints available on the Hub, and you can execute any of them using just one ollama run command.
I will take my SARA example I created using unsloth.
Go to the model’s page on Hugging Face

Download one of the GGUF model files
The larger the size, the better the quality, but it will also result in slower performance and necessitate more resources. Select from the drop down menu. I selected the 4-bit GGUF version (Q4_K_M). Then click copy.

Again open up command prompt and paste the and run the command

Follow Importing .gguf with Ollama’s Modelfile to create a Modelfile
Importing .gguf with Ollama’s Modelfile
I will take my SARA example I created using unsloth.
Generate the Modelfile
We can generate a Modelfile (you can name it as you wish) with the command, a FROM instruction that indicates the file path (the path is relative to the Modelfile):
echo --FROM Llama-3.2-SARA-3b-GGUF.F16.gguf PARAMETER temperature 0.4 PARAMETER stop "<|im_start|>" PARAMETER stop "<|im_end|>" TEMPLATE """ <|im_start|>system {{ .System }}<|im_end|> <|im_start|>user {{ .Prompt }}<|im_end|> <|im_start|>assistant """ SYSTEM """You are a helpful assistant.""" > SARAlama3.2.Modelfile
Key Points:
Alpaca Format Support:
The TEMPLATE structure aligns with Alpaca's requirements for separating system, user, and assistant inputs. This makes it easy to integrate with frameworks or tools that expect this format.
Customizable System Prompt:
The SYSTEM section ("You are a helpful assistant.") can be modified to set the tone, behavior, or specific role of the assistant. For instance, you could change it to "You are a financial advisor" or "You are a coding assistant" to tailor the model's responses.
Parameters for Fine-tuning:
Temperature 0.4: Controls the randomness of the model's responses. Lower values (like 0.4) make the output more deterministic and focused.
stop "<|im_start|>" and stop "<|im_end|>": Ensure the conversation structure aligns with Alpaca's input-output boundaries.
Importing it to Ollama
You can use the below command to import the file into Ollama, make sure you are in the same directory.
ollama create SARA-llama3.2 -f SARAlama3.2.Modelfile
If it worked you will be presetned with a success message.
Running the Model
View the models to make sure it was created using the command
ollama list 
Now to run the mdoel use the run command
ollama run SARA-llama3.2:latest